
*This article was originally published on SAS blog by Dwijendra Dwivedi
DataOps increases the productivity of AI practitioners by automating data analytics pipelines and speeding up the process of moving from ideas to innovations. DataOps best practices make raw data polished and useful for building AI models.
Models need to work on the data that is introduced, as well as on the scoring data when the model is operationalised. Combining ModelOps and DataOps can, therefore, significantly speed up the model development and deployment process. This, in turn, gives a greater return on investment in projects based on artificial intelligence or deep learning models.
This article focuses on how to bring DataOps and ModelOps together. One way of combining the two is through a centralised library of features for machine learning, or ‘feature store.’ This increases efficiency in the way features is reused. It also improves the quality because the standardisation of features creates a single accepted definition within the organisation. Introducing this library to the model development process and in an end-to-end analytical lifecycle gives multiple benefits in boosting the time to market and general effectiveness (see Figure 1).
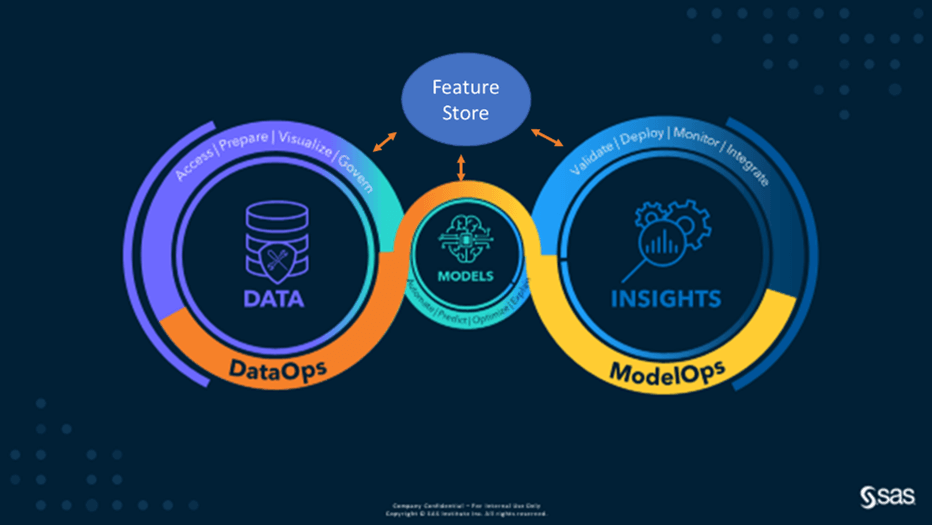
Feature store process flow
Figure 2 shows a general data interaction flow and how users interact with a feature store.
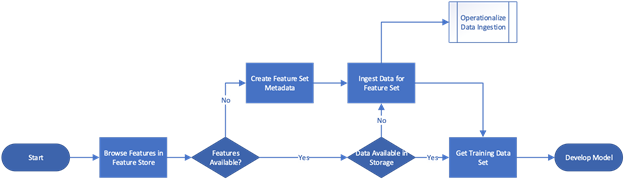
Typically, a data scientist who wanted to build a new model would start by browsing existing features in the feature store. If the desired features are unavailable, the data scientist or data engineer should create a new feature set and provide appropriate data to add to the feature store. This data can then be queried, joined and manipulated along with other feature sets to build a training set (sometimes called an Analytical Base Table) for model development. If the model is used in production, then both calculations of the data and the ingestion process should be operationalised.
If the features are already available in the feature store, the data scientist can retrieve them for model development. They may, however, need to obtain new data for selected features (for example, if the feature store contains data for 2022, but the model needs to be trained on 2021 data). The ability to search through metadata and browse existing features is essential to the development process because it shortens the development cycle and improves overall efficiency. Data preparation is the most time-consuming part of the analytical lifecycle and reusability is crucial.
Components of a feature store
A typical feature store consists of metadata, underlying storage containing calculated and ingested data and an interface that allows users to retrieve the data. The metadata may be structured and named in varying ways, and there are also differences in the interface’s capabilities and specific technologies that implement the storage. These affect the performance of the feature store and range from traditional databases through distributed file systems to complex solutions with multiple methods that may be on-premises or in public cloud services. There is also a significant difference between offline and online storage.
Offline storage is used for low-frequency, high-latency data that is computed once a day at most and usually monthly. Online storage is used for high-frequency, low-latency data that may need instant updates. This might include features like the number of clicks on the website in the past 15 minutes (providing information about the customer’s level of interest), credit card payment rejections in the last hour or the current geo-position for recommendation purposes. Online features are essential and provide a wide variety of applications in analytics. Typical use cases and main components of a feature store are shown in Figure 3.
-
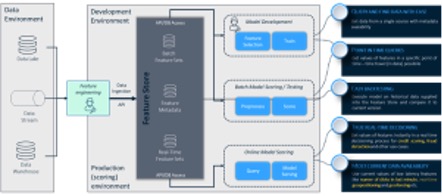
Figure 3 Logical feature store architecture and use cases
Having centrally stored features and variables allows you to monitor how, and what data is computed. Some feature stores provide statistics measuring data quality, like the number or share of missing values, and more complex approaches, including outlier detection and variable drift over time. Custom codes are used to evaluate the data and apply monitoring based on business rules. Monitoring is important for data quality, especially when combined with automated, rule-based alerts.
Key benefits and challenges of a feature store
ModelOps implementation in an organisation provides a huge efficiency gain. It reduces time to market for analytical models and improves their effectiveness through automatic deployment and constant monitoring. Feature stores add even more, enhancing and automating data preparation (through DataOps) and shortening model deployment time. Key benefits include:
- Reduced time to market through faster model development and operationalisation with data deployment in mind.
- Structured processes with a single point of entry to look up data and transparent development process with explicit responsibilities.
- Easy onboarding because data scientists can use existing features.
- Efficient collaboration because features created by one developer can be reused instantly by others.
Feature stores also bring some challenges. The most important is how to operationalise online or real-time features for models in production. This needs a streaming engine, which can differ from the data processing engine used to ingest data to the feature store. This may require recoding, which prolongs model deployment and is prone to errors.
Another problem occurs when features are available but no supporting data is in the storage. This requires users to go back to how the data was calculated and then ingest and repeat this step for the required period. This usually requires a data engineer and prolongs the model deployment procedure.
The bottom line
Bringing together DataOps and ModelOps by using a feature store allows organisations to adopt new data sources easily, create new features and operationalise them in production. This technology change leads to an organisational change in analytical lifecycle automation. DataOps action sets are the key to every digital transformation and a way to meet the requirements of a rapidly changing world.
For further reading, check out ModelOps with SAS and Microsoft, a whitepaper exploring how SAS and Microsoft have built integrations between SAS® Model Manager and Microsoft Azure Machine Learning. Both are hubs for ModelOps processes and make it possible to conduct ModelOps with the benefit of streamlined workflow management.
