

Monitoring all the events in your corporate network is big data “business.” Any observable phenomena – from logins to downloads, scripts, updates, configuration changes, etc. – happening across all the endpoints, servers, routers, switches and other infrastructure in your network can create event logs that rapidly grow to almost unimaginable mountains of data to be processed.
Inevitably, a number of events have negative consequences for your company’s security. An employee plugs a personal USB stick – compromised by a worm – into their work device and, suddenly, an adverse event! But did you set up your systems to detect those events? And now that one has happened, what are you going to do about it?
Not every adverse event merits the mobilisation of the full incident response team. Automated response plays a large part in managing the resources and time available for your IT security. Often, the danger from an adverse event can be managed well enough by a single IT administrator wielding the basic tools of the trade.
However, if your security analyst discovers a more insidious pattern and intent at play behind all those single adverse events or, alternatively, an inexplicable system failure occurs, then you probably have a security incident serious enough to warrant calling in your computer security incident response team (CSIRT). With a well-thought-out incident response plan in hand, a well-trained CSIRT can confidently buckle down and take on any adversary attacking your network.
Four Phases of Incident Response
An important standard to check your incident response plan against comes from a NIST publication called the Computer Security Incident Handling Guide (SP 800-61). The guide details four phases of incident response: Preparation; Detection & Analysis; Containment, Eradication & Recovery; and Post-Incident Activity.
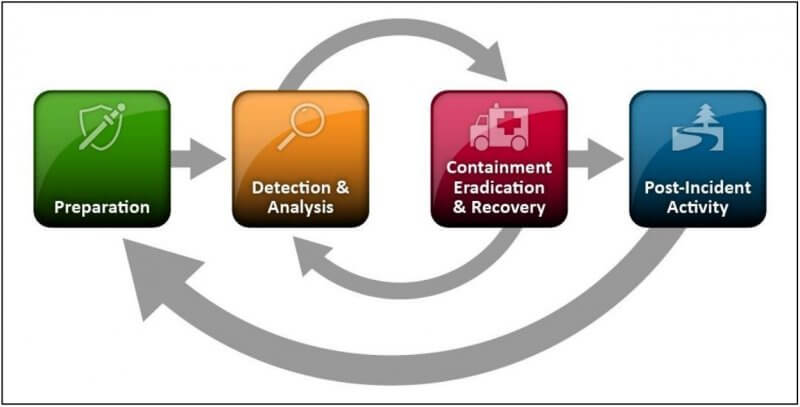
Handling incidents by following these four steps can help ensure a successful return to normal business operations. So, let’s take a look at what is involved in each step.
- Preparation
Before any incident happens, it is important to establish the proper security controls that will minimise the incidents that can happen in the first place. In other words, your corporate network needs to be built and maintained with security foremost in mind.
That includes keeping servers, operating systems and applications up to date, suitably configured and fortified with malware protection. Your network perimeter should also be properly secured via firewalls and VPNs. Don’t forget about your Achilles heel – the seemingly innocent employees at their desks. A little training can go a long way to limit the number of incidents caused by bad employee behavior.
A crucial part of setting up your network is to make sure all the necessary monitoring and logging tools are in place to collect and analyse the events happening in your network. Options range from remote monitoring and management (RMM) tools to security information and event management (SIEM) tools, security orchestration automation and response (SOAR) tools, intrusion detection systems (IDS) and intrusion prevention systems (IPS), as well as endpoint detection and response (EDR) solutions.
More threat-averse organisations, such as banks and government bodies, take advantage of threat intelligence feeds like ESET Threat Intelligence Service to provide indicators of compromise that, if found within an environment, could start off the incident response process.
Deciding which monitoring and logging tools that are appropriate for your network will have a huge impact on your CSIRT’s detection and analysis activities, as well as the remediation options available to them.
Creating an incident response team
Next, establish an incident response team and keep it trained. Smaller organisations will most likely require only a temporary team made up of existing IT admins. Larger organisations will have a permanent CSIRT that will usually bring in other IT admins from the company only to aid in specific attacks; for example, a database admin to help analyse a SQL injection attack.
Outsourcing incident response to a managed security service provider (MSSP) is also an option, although it can be costly. If you are considering this option, you should be prepared for the longer response time. Some incident response team members may need to fly to your location, which is that much more time for threats to further impact your network.
Most importantly, any CSIRT needs to have staff members on board who understand how their network is built. Ideally, they should have experience in what “normal” looks like for you and what is unusual.
Management also needs to take an active role by providing the necessary resources, funds and leadership for a CSIRT to do its work effectively. That means providing the tools, devices and jump kits that will be needed by your CSIRT, as well as making the tough business decisions brought on by the incident.
Imagine, for example, that the CSIRT discovers that the business ecommerce server is compromised and needs to be taken offline. Management needs to quickly weigh the business impact of turning off or isolating the server and communicate the final call to the CSIRT.
Other staff members and teams throughout the organisation also provide crucial support for a CSIRT. IT support staff can assist by shutting down and replacing servers, restoring from backups and cleaning up as requested by the CSIRT. Legal counsel and public relations teams are also important to manage any communication surrounding the incident with external media, partners, customers and/or law enforcement.
- Detection & Analysis
In this phase, incident response analysts bring the power of their knowledge, experience and logical thinking to bear on the multifarious forms of data presented to them by all the monitoring tools and logs to understand exactly what is happening in the network and what can be done.
The task for the analyst is to correlate events so as to recreate sequences of events leading to the incident. Especially crucial is being able to identify the root cause in order to switch to phase 3’s containment steps as quickly as possible.
However, as pictured in NIST’s incident response life-cycle diagram, phases 2 and 3 are circular, meaning that incident responders may switch back to phase 2 to conduct further root cause analysis. In this cycle, it can happen that finding and analysing some data in phase 2 suggests the need to take a particular mitigation step in phase 3. Taking that step can then uncover additional data warranting further analysis that leads to further mitigation steps, and so on.
Endpoint detection and response solutions, such as ESET Enterprise Inspector, that automatically flag suspicious events and save entire process trees for further examination by incident responders greatly bolster phase 2 activities.
- Containment, Eradication & Recovery
In the third stage, the CSIRT decides on a method to stop the further spread of detected threats. Should a server be shut down, an endpoint be isolated, or certain services be stopped? The chosen containment strategy should consider the potential for further damage, preserving evidence and the time duration of containment. Usually, this means isolating compromised systems, segmenting parts of the network, or putting affected machines in a sandbox.
Sandboxing has the benefit of allowing for further monitoring of the threat as well as collecting more evidence. However, there is a danger that a compromised host can become further damaged while in the sandbox.
Legal counsel may determine that the CSIRT should collect and document as much evidence as possible. In this case, the transfer of evidence from person to person needs to be meticulously logged.
Once contained, any discovered malware needs to be deleted from compromised systems. User accounts may need to be disabled, closed or reset. Vulnerabilities should be patched, systems and files should be restored from clean backups, passwords should be changed, firewall rules should be tightened, etc.
A full return to normal business operations can take months depending on the incident. In the short term, increased or more finely tuned logging and monitoring should be established so that IT admins can prevent the same incident from happening again. The longer term might see more overarching infrastructure changes to help transform the network into a more secure one.
- Post-Incident Activity
A CSIRT should document and provide an event reconstruction and timeline. This helps to understand the root cause of the incident and what can be done to prevent a repeat or similar incident.
This is also the time for all teams to review the effectiveness of the processes and procedures used, identify gaps in communication and collaboration difficulties, and look for opportunities to introduce efficiencies to the current incident response plan.
Finally, management needs to decide on the retention policy for evidence collected during the incident. So, don’t just the wipe the hard drives without first consulting your legal department. Most organisations archive incident records for two years to stay in compliance with regulations.
Looking to complement your incident response toolkit with powerful investigative capabilities? Get a free trial of ESET Enterprise Inspector.


